Building Kamilė
A Specialized model for Lithuanian Grammar
2026-03-19

While natural language processing has been evolving since the early days of the digital technology, for a long time, its reliability in everyday use was pretty limited (if you have already forgotten that phase, ask Siri ** Hey, Siri: this "joke" expires once Apple starts using Gemini models in its products. or Clippy ->). A massive breakthrough came in 2017-2018, when the unstoppable Moore's law and the invention of transformer architectures opened the way to large language models (LLMs). Since then, computers have become much better at understanding natural language, and a wide range of LLM-based tools for correction, translation, and editing has emerged. However, the majority of them are focused on the world's most widely spoken languages.
Still, smaller languages such as Lithuanian face their own specific set of challenges. Notably, there is significantly less publicly available high-quality data needed to train these models than for English, and our language's morphological complexity creates additional difficulties. This is exactly where specialized models can have a clear advantage. Instead of trying to solve every possible task with a single universal model, we can optimize directly for a specific problem, such as Lithuanian spelling and grammar correction.
In this post, we share what the Kablelis team learned from training over 70 language models, and how we handled the specific challenges of the Lithuanian language.
Lithuanian Language Data
If you're looking for data to train language models, you don't need to look far: the internet is the largest and most easily accessible source. And there is a lot of text in it. So much that it is hard not to emphasize these models' ability to process superhuman amounts of information. ** Reading 8 hours per day, it would take an average person about 100,000 years to fully read the dataset shown below.
But once you take a closer look at these corpora, one things stands out. English clearly dominates, with a volume exceeding all other languages combined. The chart below shows that Lithuanian remains among the least represented official European languages in internet datasets (ahead of only Latvian, Estonian, and Slovenian).
European language data volume for LLM training (Terabytes (TB); Common Crawl 2025)
Since English remains the default language of global digital communication, this gap will likely keep growing overtime. Language models are really reliant on high quality data, so if we want smaller languages to stay relevant in the internet era, we need to actively invest in their future.
Of course, the internet is not the only viable source of text, but collecting and processing data from elsewhere is much harder and requires substantial investment.
Problem #1: lack of easily accessible Lithuanian-language data.
Lithuanian Language Characteristics
Data scarcity is not the only challenge - Lithuanian is morphologically far more complex than English.
To illustrate this, let us compare the simple verb "naudoti" with its English equivalent "(to) use". The number of forms that can be derived from these word roots differs drastically: Lithuanian has dozens of times more possible correct derivatives. And this pattern repeats not just for one isolated word, but across the language as a whole.
Map of forms and derivatives of the word "use"
in English (69 words).
Interactive map of forms and derivatives of the word "naudoti"
in Lithuanian (5,644 words).
Looking at the Lithuanian form map above, we can see an important nuance: even though there are thousands of correct word forms, a large percentage of them are rarely used in everyday language. Consequently, these rare forms simply don't appear in internet corpora, causing uncertainty in the models' predictions. This means publicly available internet data alone is not enough - additional strategies are needed to train high-quality models.
Problem #2: because of Lithuanian language complexity, training high-quality models requires more data.
Synthetic Data Generation
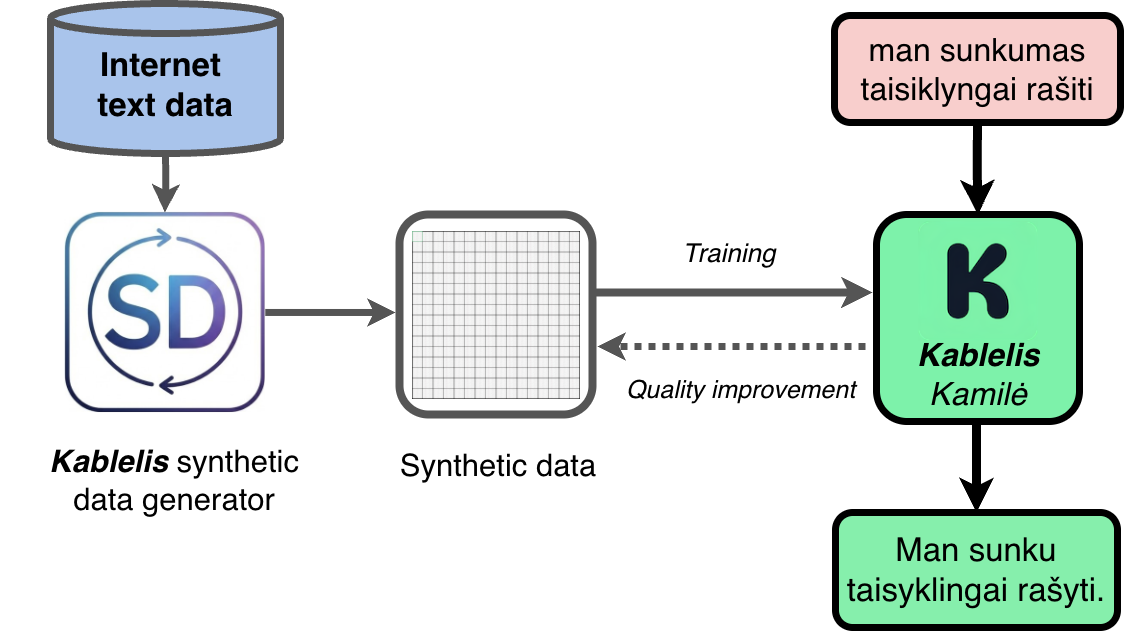
At Kablelis.lt, our models specialize strictly in spelling and grammar correction. The scope of this problem is much easier to cover than building general-purpose models (GPT-N, Gemini, Claude). The key advantage of this specialization is that we can synthetically generate the required data ourselves and directly address the issues mentioned above.
To do this effectively, we need many different, realistic ways to "corrupt" text. While improving Kablelis data pipeline, we went through many iterations, and today, its core engine is the ability to systematically transform word forms (altering cases, tenses, and other grammatical rules).


Derived forms of the words "naudoti" and "teising(as/a)".
Combined with the insertion of many other error types, we can mass-produce faulty text that perfectly mimics the kind of mistakes people make when they are rushing or after they've lost a couple hours of sleep.

Synthetic data generation process.
Since we know exactly how the text looked before we corrupted it, the model's objective becomes clear - take the broken text and return it to its original form. With millions of such examples, we can train models and steadily drive up correction quality. This also allows us to track exactly which error types the model struggles with and dynamically generate more of them during the next training run.
Results
How do we know if all of this actually worked?
We can measure it by taking a large corpus (50,000+ words) with a large number of diverse errors (over 10,000) and evaluating each model's ability to correct them accurately.
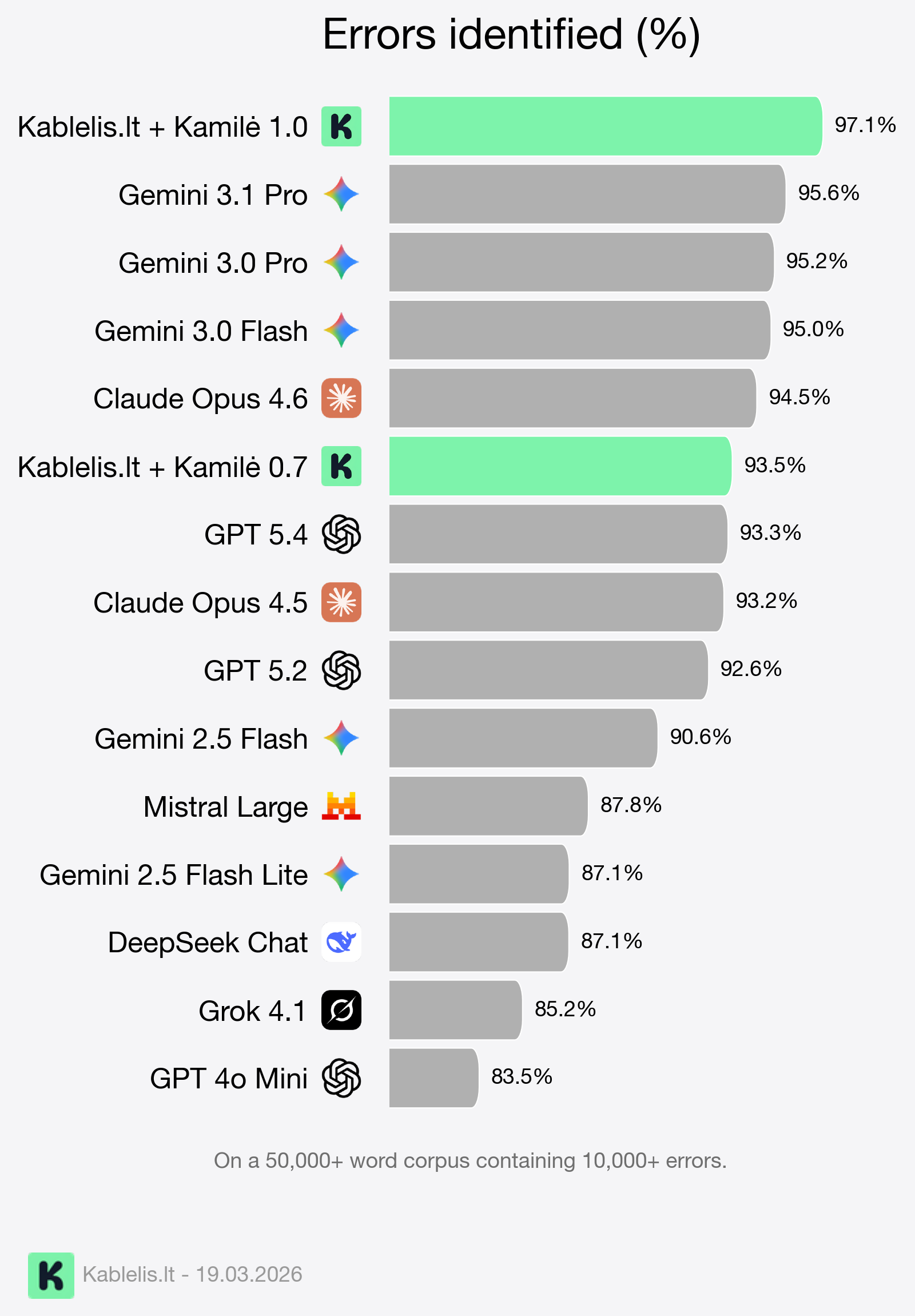
We can see that when pitted against the biggest general LLMs on the market, our models, combined with the Kablelis dictionary system, take the lead in this task.
Ultimately, this proves that for targeted domains, specialization can beat general scale. More importantly, as we inch closer towards the magical 100% mark, it gives our users the confidence to trust our models.
What Next?
While we have progressed significantly over the past year, the world does not stand still. Almost every month, tech giants release new models that raise the baseline. But the Kablelis team isn't slowing down, and we are committed to keeping our moat in this specific niche.
Our next steps are improving style, tone, and semantic consistency across long documents, and reducing model response latency.
Our long-term goal remains the same: to give everyone easy access to the highest-quality Lithuanian correction and editing models, and integrate them into as many writing platforms as possible.
Have questions or suggestions? Write to us - we will gladly share more technical details.
P.S. Kablelis was very useful while writing this post, but we shall keep the exact number of mistakes found to ourselves.