Kaip apmokėme lietuvių kalbos taisymo modelį „Kamilė"
2026-03-19

Nors kalbos apdorojimo technologijos vystomos nuo pat skaitmeninės eros pradžios, ilgą laiką jų patikimumas kasdienėms reikmėms buvo gan ribotas (jei jau spėjote pamiršt tą etapą, pasiklauskit Siri ** Hey, Siri: šio „juokelio" galiojimo laikas baigsis Apple pradėjus naudoti Gemini modelius savo produktuose. arba Clippy→). Ryškus lūžis įvyko 2017–2018 m., kai transformerių architektūros išradimas atvėrė kelią didiesiems kalbos modeliams (DKM / angl. LLM). Nuo tada kompiuteriai ėmė gerokai tiksliau suprasti natūralią kalbą ir atsirado galybė DKM-ais pagrįstų kalbos taisymo, vertimo, redagavimo įrankių, dauguma kurių yra orientuoti į dažniausiai vartojamas kalbas.
Vis dėlto mažesnėms kalboms, tokioms kaip lietuvių, atsirado savas iššūkis: viešai prieinamų kokybiškų duomenų, kurie būtini šiems modeliams treniruoti, yra ženkliai mažiau nei anglų kalbai, o mūsų kalbos morfologinis sudėtingumas kelia jiems papildomų keblumų. Būtent šioje vietoje specializuoti modeliai gali turėti aiškų pranašumą. Vietoje bandymo spręsti visas įmanomas užduotis vienu universaliu modeliu, galima kryptingai optimizuoti konkrečią problemą, pavyzdžiui, lietuvių kalbos rašybos ir gramatikos taisymą.
Šiame įraše dalinamės, ko Kablelyje išmokome treniruodami daugiau nei 70 kalbos modelių ir kaip dorojomės su lietuvių kalba susijusiais iššūkiais.
Lietuvių kalbos duomenys
Ieškant duomenų kalbos modelių treniravimui, toli dairytis nereikia – internetas yra didžiausias ir lengviausiai prieinamas jų šaltinis. Ir teksto jame yra daug. Tiek daug, kad sunku nepabrėžti šių modelių gebėjimo susidoroti su nežmoniškais informacijos kiekiais. ** Skaitant po 8 val. per dieną, pilnai perskaityti žemiau pateiktą duomenų rinkinį vidutiniam žmogui reikėtų apie 100,000 metų.
Atidžiau pažvelgus į šių tekstynų turinį, iškart matome „problemą“: jame aiškiai dominuoja anglų kalba ir jos kiekis viršija visų kitų kalbų kiekį kartu sudėjus. Apačioje matome, kad lietuvių kalba interneto duomenų rinkiniuose lieka tarp prasčiausiai reprezentuotų oficialių Europos kalbų (aukščiau tik už latvių, estų ir slovėnų).
Europos kalbų duomenų kiekis DKM treniravimui (Terabaitais (TB); Common Crawl 2025)
Ilgainiui šis skirtumas greičiausiai tik didės, nes anglų kalba išlieka pagrindine pasauline skaitmeninės komunikacijos kalba. Vadinasi, jei norime išlaikyti mažesnių kalbų gyvybingumą interneto amžiuje, turime aktyviai investuoti į jų ateitį.
Žinoma, internetas nėra vienintelis teksto šaltinis, bet surinkti ir apdoroti duomenis iš kitur yra gerokai sunkiau, tam reikia didelių lėšų bei laiko indėlio.
Problema #1: lengvai prieinamų lietuviškų duomenų trūkumas.
Lietuvių kalbos ypatybės
Duomenų stygiaus problema nėra vienintelė – lietuvių kalba morfologiškai yra gerokai sudėtingesnė nei anglų.
Tam iliustruoti palyginkime paprastą veiksmažodį „naudoti“ ir jo anglišką atitikmenį „(to) use“. Iš šių žodžių šaknų sudaromų formų skaičius skiriasi drastiškai: lietuvių kalboje galimų taisyklingų darinių yra keliasdešimt kartų daugiau. Ir ši tendencija pasikartoja ne su vienu pavieniu žodžiu, o visos kalbos lygyje.
Žodžio „use" formų ir darinių
anglų kalboje žemėlapis (69 žodžiai).
Interaktyvus žodžio „naudoti" formų ir darinių
lietuvių kalboje žemėlapis (5,644 žodžiai).
Pažvelgę į aukščiau esantį lietuviškų formų žemėlapį matome svarbų niuansą: nors taisyklingų žodžių yra labai daug, didelė jų dalis kasdienėje kalboje yra vartojama labai retai. Dėl to tokių formų dažnai nėra ir interneto tekstynuose, o kalbos modeliai jų taisyklingumą vertina su didesne paklaida. Tai reiškia, kad vien viešai prieinamų interneto duomenų neužtenka - kokybiškiems modeliams treniruoti reikia papildomų strategijų.
Problema #2: dėl lietuvių kalbos sudėtingumo modeliams treniruoti reikia daugiau duomenų.
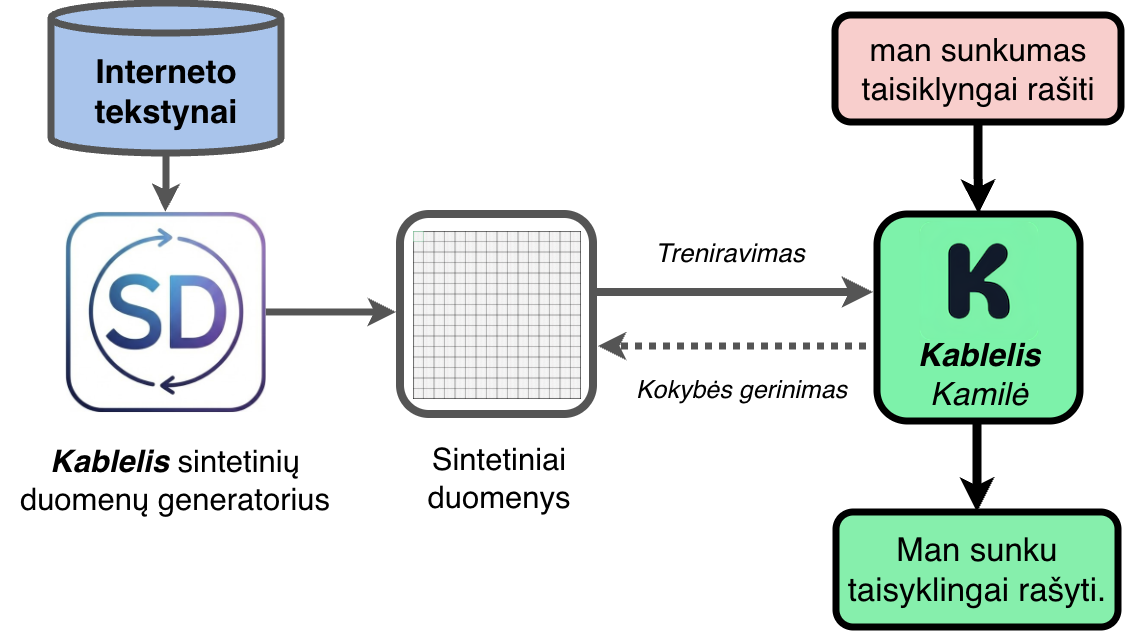
Sintetinių duomenų generavimas
Kablelis.lt kalbos modeliai specializuojasi rašybos klaidų taisymo užduotyse. Šios problemos apimtis yra daug lengviau aprėpiama, palyginus su bendrojo pobūdžio modelių kūrimu (GPT-N, Gemini, Claude). Esminis šios specializacijos pranašumas tas, kad reikalingus duomenis galime susigeneruoti patys sintetiniu būdu ir taip kryptingai kovoti su anksčiau minėtomis problemomis.
Efektyviai tam įgyvendinti reikia daug skirtingų, realistiškų būdų tekstui „sugadinti“. Tobulindami Kablelio duomenų sistemą perėjome daug iteracijų, o dabartinė jos šerdis yra gebėjimas sistemiškai kaitalioti žodžių formas (linksnius, laikus ir kitas gramatines ypatybes).


Žodžių „naudoti“ ir „teising(as/a)“ išvestinės formos.
Tą sujungę su kitų įvairaus pobūdžio klaidų įterpimu, galime masiškai generuoti klaidingus tekstus, kurie primena kažką, ką patys kartais parašome skubėdami ar prasčiau išsimiegoję.

Sintetinių duomenų generavimo procesas.
Kadangi žinome, kaip tekstas atrodė prieš klaidų įterpimą, kalbos modelio užduotis tampa aiški - gavus klaidingą tekstą atkurti teisingą jo formą. Turėdami milijonus tokių pavyzdžių, galime pradėti treniruoti modelius ir nuosekliai kelti taisymo kokybę. Taip pat galime sekti kurie klaidų tipai modeliams kelia didžiausią iššūkį ir jų daugiau naudoti treniravimo metu.
Rezultatai
Kaip įvertinti ar visa tai pasiteisino?
Pamatuoti galime paėmę didelės apimties tekstyną (50,000+ žodžių) su dideliu įvairaus pobūdžio klaidų skaičiumi (daugiau nei 10,000) ir bandydami įvertinti kiekvieno modelio gebėjimą jas teisingai ištaisyti.
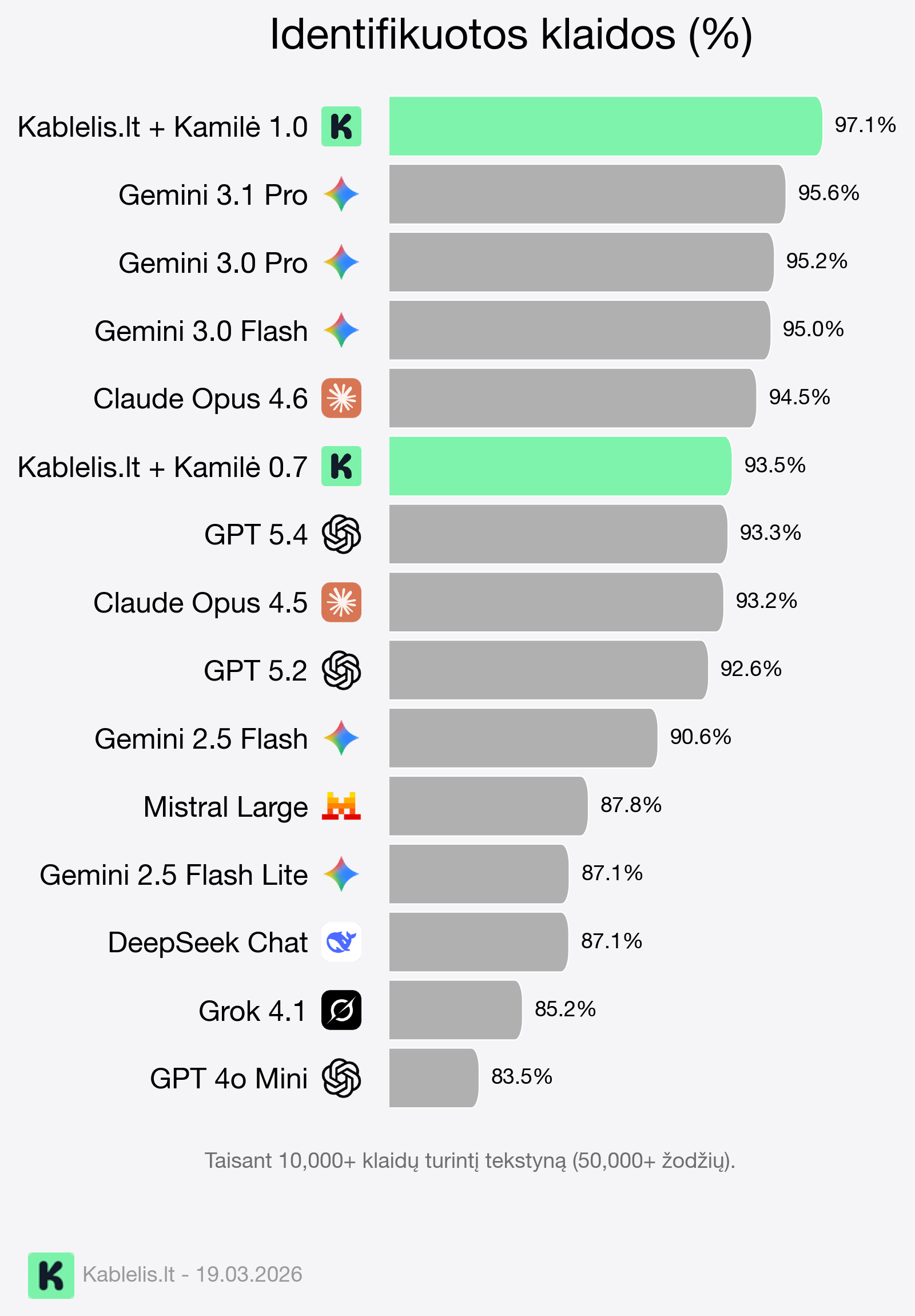
Matome, kad lyginant su pagrindiniais garsiausiais žaidėjais, mūsų modeliai, sujungti su Kablelio žodyno sistema, pirmauja šios užduoties fronte.
Galiausiai tai įrodo, kad aiškiai apibrėžtų užduočių atveju, specializuoti modeliai gali nurungti mastą. Dar svarbiau – mums vis labiau artėjant prie magiškos 100% ribos, auga pasitikėjimas mūsų sistema.
Kas toliau?
Nors per metus pasistūmėjome daug, pasaulis vietoje nestovi: vos ne kas mėnesį technologinių gigantų leidžiami modeliai vis kelia mums kartelę. Tačiau Kablelio komanda pilna idėjų ir mes esame pasiryžę toliau plėsti pranašumą savojoje nišoje.
Sekantys mūsų žingsniai – ilgų tekstų stiliaus, tono ir semantinio nuoseklumo užtikrinimas visame dokumente, bei į modelio atsako (latency) mažinimas.
Ilgalaikis mūsų tikslas: suteikti visiems lengvą prieigą prie kokybiškiausių lietuvių kalbos taisymo ir redagavimo modelių ir juos integruoti į kuo daugiau rašymo platformų.
Turite klausimų ar pasiūlymų? Rašykite mums – mielai pasidalinsime daugiau techninių detalių.
P.S. Kablelis buvo labai naudingas rašant šį įrašą, o surastų klaidų skaičių geriau pasiliksime sau.